Scanner Basics
I've been playing with this tuning business for almost six years now, and one of the things that keeps me baffled is how come people still don't use the scanner to its full potential. The scanner is the doorway into a goldmine of information, so it would logically follow that mastering operating that door would be crucial. Thus, in this post I'm trying to show few simple tricks and setups that can give you more insight.
The graph below I call the 'Street Dyno,' and it is the simplest, the most fundamental graph for assessing performance. DynAir is basically HP, and DynCylAir is TQ. They're directly related, so I use these two pairs interchangeably. With this in mind, the bottom graph is your typical dyno chart, except in terms an engine management system can understand. The top graph has RPM and Throttle, and they're there mostly for reference, so you know when you went WOT and how far did you get on RPM. The unique thing of this particular data is that by about 7000 RPM, the Dynamic Airflow gets pegged at the maximum of 512g/sec, which is an internal limitation of this ECU. Also, for Throttle, I changed the scale to go not from 0 to 100, but 0 to 105, so when you go WOT, you don't have the Throttle line overlapping on the edge of the whole graph, as sometimes, depending on color combinations it might effectively 'disappear.' Simple trick, but useful sometimes.

On this graph, you also have time, so in this case you get one gear 'pull' which is nature's way of 'integrating the area under the curve'. It is a very good way of assessing the full power, not just looking at peak numbers. If you got few different settings you want to try, this is the chart you want to use. Make your changes, keep doing the same run, compare how long it takes to traverse the same intervals of RPMs, and you'll get much closer to the optimal AFR and spark combination. To gain precision it also helps to keep the number of scanned PIDs to minimum. The number changes for different ECU's, so I'll let you figure out from HPT's help files how much is too much for your particular platform/year/model.

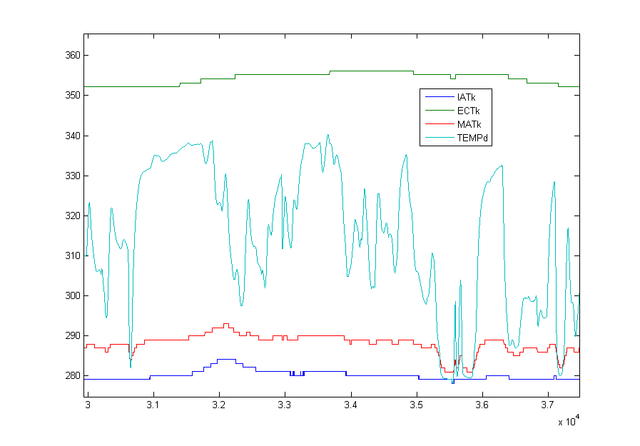
The graph above is 'Street Dyno' with the addition of temperatures, which often are an indicator of hardware issues. Both AFR and spark have multiple modifier tables that are referenced against ECT or IAT, so it's good to know both temps are in a 'healthy' range, and not introducing more problems indirectly by altering your fueling or timing. If your IAT goes up and not down as you increase your speed, your intake is not getting any of the cold, moving air; take a look at your airbox, how it seals, whether it takes in cold outside air, or warm engine bay air. Similarly, ECT should get some better cooling at speed, if it doesn't, you need to look if the air is going through the radiator instead of around it. This graph is an example of a healthy setup. IAT drops the moment you increase your airflow, and ECT follows, it's just slower to react as it deals with liquid not gas. Another addition to this graph is Knock Retard, which i purposely placed right against the horizontal divider to show you how sometimes even despite different colors, graphs can be nearly invisible. It might be visible on your computer at home, but how visible would it be on a small laptop screen with the 'high gloss' coating? Sometimes you have to help your hardware with small tricks like I've described in the previous section.

This setup is all about fuel monitoring. It lets you know if your injectors' fuel flow is keeping up with the airflow. The base on the bottom is just in the previous graphs, the 'dyno' graph. But now we also get to monitor AFRs and IPWs. It's good to know that both banks of injectors are in good working order, and it's usually easy to see when one side is quite different from the other. It's important to have both injector settings set up to the same scale, as this way if they're identical you will see one line, but if there's discrepancies, it's easy to see the two lines diverging.
Similar trick is used for the AFRcommanded vs AFRwb. If you set them up on the same scale, they should follow each other closely. Of course widebands aren't very precise instruments, so even on a well tuned car expect some jitter. In this case, when the car is just cruising, you can see the AFRwb get a little off on shifts, but the moment the car goes WOT, the AFRwb follows AFRcommanded very nicely.
Another thing on this graph is the Injector Duty graph. It's a good quick indicator if you're not stressing your fuel system too much. On this graph you have a system that's utilized to the fullest, but doing it safely. At peak it reaches about 90% of it's full potential, which is about as high as you'd want to go.

This graph is about Timing vs Torque. This setup usually takes some fiddling with scales of both measures. Peak TQ means the highest compression, which means the highest flame front speed, thus needing the least time to burn the entire mixture. Thus peak TQ should be accompanied by the lowest spark advance. So in general, peak in one should be the valley in the other. As you can see in this pic, that's usually the case. The highest the green line goes, the lower the red line gets, and vice versa. I placed the white vertical line at the peak TQ (or in this case, airmass, which as I've mentioned, are conceptually interchangeable) to see if it matches the lowest valley in the spark graph. It doesn't, it's not far, but it might be something to adjust, if ever so slightly. Also, we can see that the timing is fairly low on the beginning of the WOT run, in lower RPM. Since the airmass isn't very high there, we could probably gain a good amount of power by upping the timing in that range.
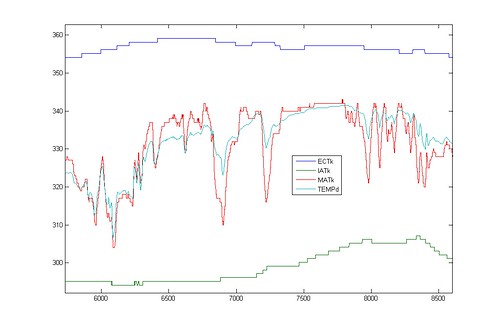
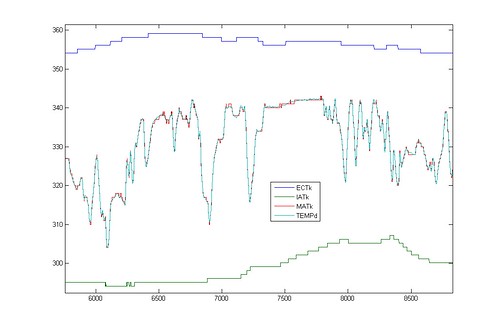
After I wrote this post, I sent the draft to few friends, to get some feedback, and lo and behold, one of them found something in the logs that I overlooked. Look at the graph comparing the two oxygen sensors (the narrowbands)

One of the sensors is dead. No matter what happens, it gives the same output. The other sensor shows signs of life just fine.
And this is probably the most important point of looking at logs. If you're like me and looked at the WOT data, because that's what I was asked to do, you might skip over important bits of information, which seem to be irrelevant; after all why would I look at narrowbands during WOT? Someone with a fresh set of eyes and less bias might come in and spot something as important as a dead sensor right away. Reading logs is all about a scientific approach--don't go in with expectations, because you will only see what you want to see, and not what's truly there. After all, you want to learn/spot something new, don't you?
Labels: scanner
posted by Marcin @ 5:22 PM
5 comments
![]()
![]()